Detecção de Compostos Orgânicos Usando Luz Visível
Cientistas da Universidade de Santiago do Chile e da Universidade de Notre Dame desenvolveram uma abordagem baseada em aprendizado de máquina para reconhecer compostos orgânicos por seu índice de refração em um determinado comprimento de onda óptico. Este método tem o potencial de automatizar a análise química e torná-la mais acessível, segura e menos dependente de habilidades especializadas. Como resultado, pode ter usos industriais e de pesquisa.
Métodos e passos na criação da máquina de identificação de compostos orgânicos
Os cientistas publicaram um artigo intitulado “Identificação de aprendizado de máquina de compostos orgânicos usando luz visível” no The Journal of Physical Chemistry A. Neste artigo, eles descrevem sua abordagem inovadora para coletar um conjunto de dados distinto e construir um protótipo de sensor de química orgânica usando as técnicas descritas.
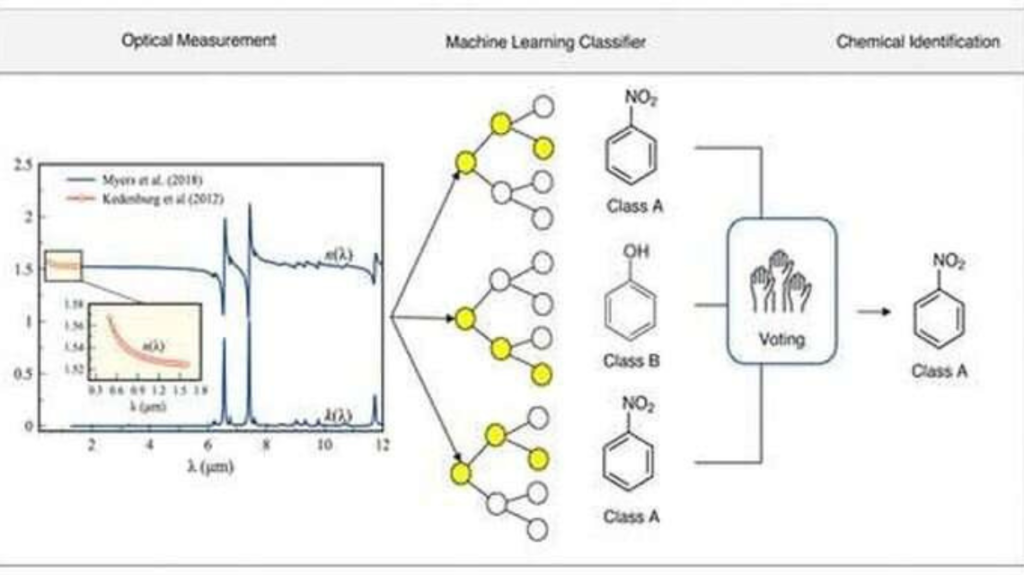
Portanto, os cientistas treinaram o aprendizado de máquina em um banco de dados publicamente acessível de experimentos ópticos contendo dados publicados da literatura científica desde 1940. Embora, eles descobriram todos os parâmetros necessários no banco de dados para construir perfis de identificação para 61 moléculas orgânicas, incluindo velocidade e dispersão de grupo, comprimento de onda de medição faixa, estado da amostra, índices de refração e coeficientes de extinção em uma ampla faixa de comprimentos de onda. Eles usaram um total de 194.816 registros espectrais de índice de refração e curvas de extinção dos 61 compostos orgânicos e polímeros no banco de dados.
Entretanto, em um sensor de classificação molecular infravermelho (IR) padrão, a análise de sua absorção Raman e picos de dispersão identifica a molécula, resultando em uma impressão digital única que corresponde a um banco de dados. No entanto, o índice de refração estático de compostos orgânicos é uma característica única que carece do mesmo nível de informação codificada. Da mesma forma, os bancos de dados de índice de refração em comprimentos de onda individuais fora das ressonâncias de absorção ultravioleta e infravermelha não fornecem informações suficientes, o que pode explicar por que eles não usaram luz visível para classificar moléculas orgânicas.
Os testes iniciais
Após testes iniciais com dados brutos, que resultaram em uma taxa de precisão de 80%, os cientistas buscaram melhorar ainda mais os resultados. Eles descobriram que o banco de dados original não era otimizado para aprendizado de máquina, pois muitas das informações vinham de pesquisas realizadas antes do advento dos computadores domésticos. O banco de dados continha uma grande quantidade de informações sobre comprimentos de onda nas faixas ultravioleta e infravermelha, nas quais a IA estava sendo treinada. Como resultado, os pesquisadores decidiram adotar uma abordagem mais direcionada.
Os cientistas usaram várias técnicas de pré-processamento de dados para simular um ambiente de aprendizado ideal para a IA. Eles pretendiam desenvolver um conjunto de dados equilibrado para evitar que a IA desse preferência a recursos específicos devido à quantidade de informações disponíveis. Para minimizar o impacto dos comprimentos de onda de infravermelho no conjunto geral de dados, eles empregaram técnicas de superamostragem, subamostragem e aumento baseado em física. Ao treinar a IA nos dados pré-processados balanceados, os pesquisadores conseguiram obter precisões de teste de classificação molecular acima de 98% nas regiões visíveis.
Mais estudos são necessários de acordo com os pesquisadores
Os cientistas reconhecem que mais pesquisas são necessárias para ampliar e generalizar o classificador para reconhecer as propriedades estruturais e químicas das moléculas encontradas no banco de dados de índice de refração. Em conclusão, eles observam que seu trabalho serve como uma base promissora para a criação de sensores químicos remotos.
Leia o artigo original em: PHYS ORG
Leia mais: Não culpar as mulheres é fundamental para aumentar sua presença nas profissões de STEM